点击上方 "大数据肌肉猿"关注,星标一起成长点击下方链接,进入高质量学习交流群今日更新| 950个转型案例分享-大数据交流群本文目录:一、行列转换二、排名中取他值三、累计求值四、窗口大小...
”sql hive 求职面试 面试题“ 的搜索结果
Hive经典面试实操sql题,面试实操题,学习练手题
HiveSQL面试练习题
标签: 求职面试
HiveSQL面试练习题

SQL常见面试题总结
以下文章来源于大数据技术...专注分享数据仓库与大数据技术(Flink/Hadoop/Spark/Hive)相关内容。关注我可以免费领取大数据书籍与视频。我的博客:https://jiamaoxiang.top/ 第一题 需求 我们有如下的用户访问数据 ...
此场景在工作中遇到过,笔者原创。有用户表user,字段user_id, city。现运营同事要选10w人发调查问卷,要求人群的city分布,和全量用户的city分布一致。 with city_fenbu as ( select city, user_cnt/ sum(user_...
Hive高频面试题。

Hive SQL 2023必考常用窗口函数及面试题

真实数仓sql面试题(一)
内部表:通过create table 表名的方法,生成的表格,表格的文件夹的位置在/user/hive/warehouse/数据库名.db,并且表格的文件夹是自动生成的。分桶在表连接的时候,才会用到,可以加快两张表联合查询的速度,只有当...

本套SQL题的答案是由许多小伙伴共同贡献的,1+1的力量是远远大于2的,...最强最全面的大数据SQL经典面试题完整PDF版 一、行列转换 描述:表中记录了各年份各部门的平均绩效考核成绩。 表名:t1 表结构: a--年份..
大数据面试题及答案【最新版】大数据高级面试题大全(2021版),发现网上很多大数据面试题都没有答案,所以花了很长时间搜集,本套大数据面试题大全 最近由于要准备面试就开始提早看些面试、笔试题。以下是自己总结的...
今天,和大家分享一些数据仓库工具hive相关的面试题!有3种join方式:① 在 reduce 端进行 join,最常用的 join 方式。Map端的主要工作:为来自不同表(文件)的 key/value 对打标签以区别不同来源的记录。
本套大数据SQL题不仅题目丰富多样,答案更是精彩绝伦!注:以下参考答案都经过简单数据场景进行测试通过,但并未测试其他复杂情况。本文档的SQL主要使用。



例如,市场分析、创建财务报表、创建计划等日常性商务工作。窗口函数就是为了实现OLAP 而添加的标准SQL 功能。 0.窗口函数的分类 按照功能划分: 序号函数:row_number() / rank() / dense_rank() 分布函数:...

无论是秋招、春招或者是实习,sql都是面试官考察的重点,拿刚刚过去的19秋招来说,搜狐、网易、京东等在数据分析师岗位面试时都考了sql,而拼多多在数据分析笔试时就安排了四到五道复杂的sql题,虽然实习的难度会比...
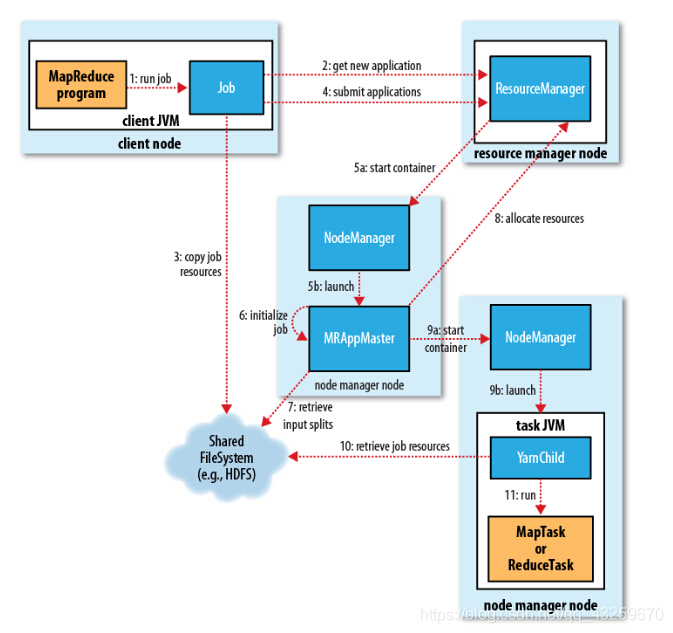
真实数仓sql面试
文章目录Impala概述Impala特点Impala劣势Impala架构核心组件Statestore DaemonCatalog DaemonImpala Daemon(impalad)整体架构流程Impala与hive的异同数据存储元数据SQL解释处理执行计划数据流内存使用调度 ...

概述2019 年是大数据实时计算领域最不平凡的一年,2019 年 1 月阿里巴巴 Blink (内部的 Flink 分支版本)开源,大数据领域一夜间从 Spark 独步天下走向了两强争霸...
大数据面试题总结一波,助力准备在年底跳槽寻找好工作的小伙伴们,只有度过笔试这一关才能在下面的关卡中大展宏图!Hadoop,Spark,Flink,数据仓库,10多个技术面、100多道面试题,为你的面试保驾护航。
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地